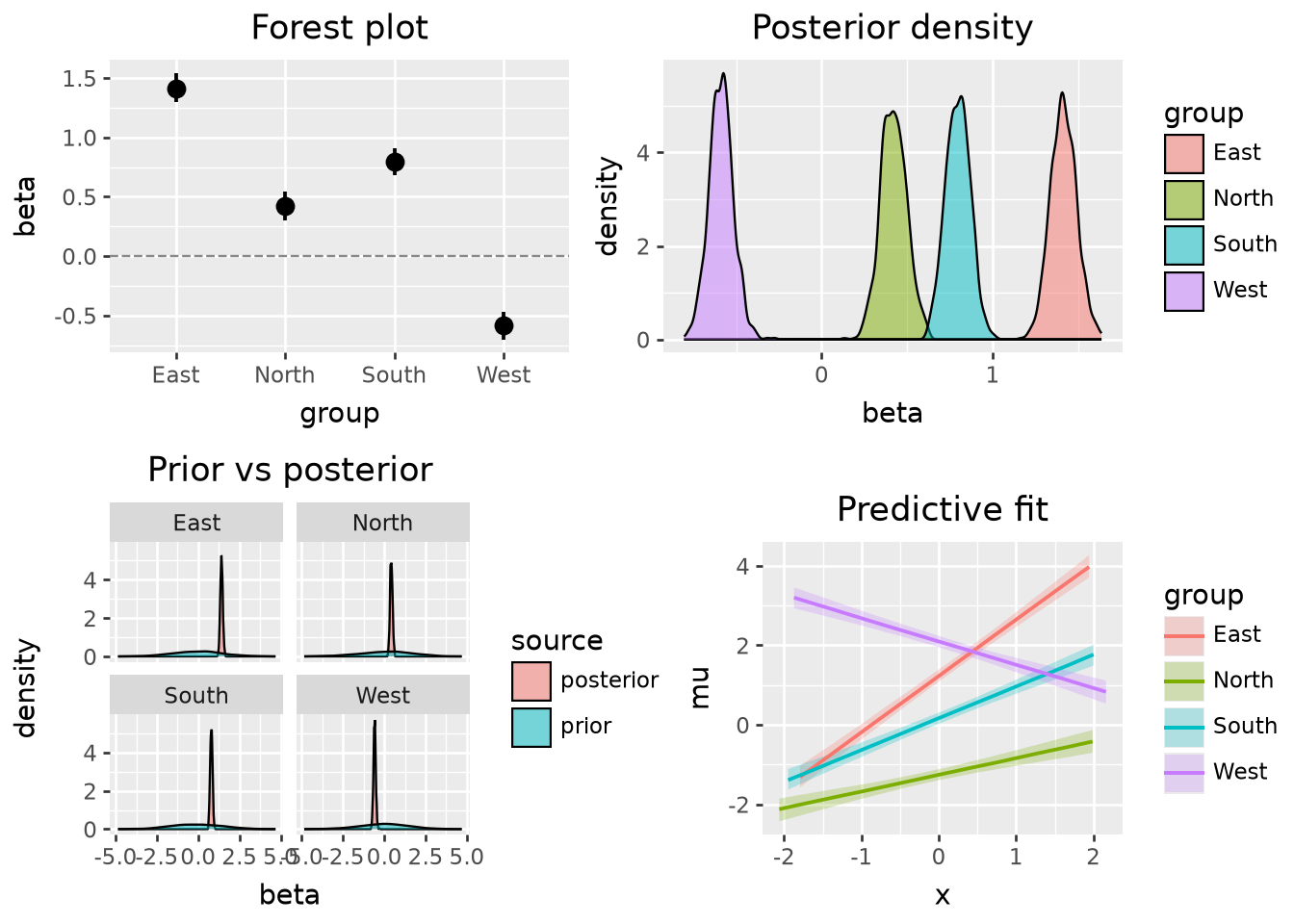
A tidybayes-inspired data layer for declarative Bayesian visualisation in Python.
A tidybayes-inspired data layer for declarative Bayesian visualisation in Python.
tidydraws turns MCMC output (ArviZ) into tidy Polars frames that are ready to plot — one .to_pandas() away from any ggplot-like backend. It does no plotting itself. Four functions, four roles:
Code
from pathlib import Path
import sys
import lets_plot as lp
import plotnine as p9
import seaborn as sns
import seaborn.objects as so
from matplotlib.figure import Figure
import altair as alt
import pandas as pd
import polars as pl
import pymc as pm
import tidydraws as td
for parent in [Path.cwd(), *Path.cwd().parents]:
helper_dir = parent / "docs" / "examples"
if (helper_dir / "_pymc_workflow.py").exists():
sys.path.insert(0, str(helper_dir))
break
from _pymc_workflow import simulate_grouped_regression
lp.LetsPlot.setup_html()
workflow = simulate_grouped_regression(seed=2026)
observed = workflow.observed.with_columns(pl.col("groups").alias("group"))
coords = {
"groups": workflow.group_names,
"obs_ind": observed.get_column("obs_ind").to_numpy(),
}
with pm.Model(coords=coords) as model:
x = pm.Data("x", observed.get_column("x").to_numpy(), dims="obs_ind")
group_idx = pm.Data(
"group_idx",
observed.get_column("group_idx").to_numpy().astype("int64"),
dims="obs_ind",
)
intercept = pm.Normal("intercept", mu=0.0, sigma=2.0, dims="groups")
beta = pm.Normal("beta", mu=0.0, sigma=1.5, dims="groups")
sigma = pm.HalfNormal("sigma", sigma=1.0)
mu = pm.Deterministic(
"mu",
intercept[group_idx] + beta[group_idx] * x,
dims="obs_ind",
)
pm.Normal(
"y",
mu=mu,
sigma=sigma,
observed=observed.get_column("y").to_numpy(),
dims="obs_ind",
)
prior = pm.sample_prior_predictive(
draws=800,
random_seed=2029,
var_names=["intercept", "beta", "sigma"],
)
dt = pm.sample(
draws=400,
tune=400,
random_seed=2026,
progressbar=False,
compute_convergence_checks=False,
)
pm.sample_posterior_predictive(
dt,
var_names=["mu"],
predictions=True,
extend_inferencedata=True,
random_seed=2028,
progressbar=False,
)
# arviz 1.0+ uses .update(), 0.x uses .extend()
try:
dt.update(prior)
except AttributeError:
dt.extend(prior)
beta_df = td.parameter_draws(dt, "beta")
beta_summary = td.point_interval(beta_df, "beta", group_by="groups").sort("groups")
compare = td.compare_draws(dt, "beta")
pred = td.prediction_draws(dt, newdata=observed, var_name="mu")
pred_summary = td.point_interval(pred, "mu", group_by=["obs_ind", "x", "group"]).sort(
"x"
)
Plot
p_forest = (
lp.ggplot(beta_summary.to_pandas(), lp.aes("groups", "beta"))
+ lp.geom_pointrange(lp.aes(ymin="beta_lower", ymax="beta_upper"), size=0.8)
+ lp.geom_hline(yintercept=0, linetype="dashed", color="#888888")
+ lp.labs(x="group", y="beta", title="Forest plot")
)
p_density = (
lp.ggplot(beta_df.to_pandas(), lp.aes("beta", fill="groups"))
+ lp.geom_density(alpha=0.5)
+ lp.labs(x="beta", y="density", fill="group", title="Posterior density")
)
p_compare = (
lp.ggplot(compare.to_pandas(), lp.aes("beta", fill="source"))
+ lp.geom_density(alpha=0.5)
+ lp.facet_wrap(facets="groups", ncol=2)
+ lp.labs(x="beta", y="density", fill="source", title="Prior vs posterior")
)
p_pred = (
lp.ggplot(pred_summary.to_pandas(), lp.aes("x"))
+ lp.geom_ribbon(
lp.aes(ymin="mu_lower", ymax="mu_upper", fill=lp.as_discrete("group")),
alpha=0.25,
)
+ lp.geom_line(lp.aes(y="mu", color=lp.as_discrete("group")), size=0.8)
+ lp.labs(x="x", y="mu", color="group", fill="group", title="Predictive fit")
)
g = lp.gggrid([p_forest, p_density, p_compare, p_pred], ncol=2)
lp.ggsave(g, "index-plot.png", path="../docs/assets", scale=1.5)
g
Fontconfig error: Cannot load default config file: No such file: (null)
p9_forest = (
p9.ggplot(beta_summary.to_pandas(), p9.aes("groups", "beta"))
+ p9.geom_pointrange(p9.aes(ymin="beta_lower", ymax="beta_upper"), size=0.8)
+ p9.geom_hline(yintercept=0, linetype="dashed", color="#888888")
+ p9.labs(x="group", y="beta", title="Forest plot")
)
p9_density = (
p9.ggplot(beta_df.to_pandas(), p9.aes("beta", fill="groups"))
+ p9.geom_density(alpha=0.5)
+ p9.labs(x="beta", y="density", fill="group", title="Posterior density")
)
p9_compare = (
p9.ggplot(compare.to_pandas(), p9.aes("beta", fill="source"))
+ p9.geom_density(alpha=0.5)
+ p9.facet_wrap("~groups", ncol=2)
+ p9.labs(x="beta", y="density", fill="source", title="Prior vs posterior")
)
p9_pred = (
p9.ggplot(pred_summary.to_pandas(), p9.aes("x"))
+ p9.geom_ribbon(
p9.aes(ymin="mu_lower", ymax="mu_upper", fill="group"),
alpha=0.25,
)
+ p9.geom_line(p9.aes(y="mu", color="group"), size=0.8)
+ p9.labs(x="x", y="mu", color="group", fill="group", title="Predictive fit")
)
(p9_forest | p9_density) / (p9_compare | p9_pred)
so.Plot.config.theme.update(sns.axes_style("whitegrid"))
fig = Figure(figsize=(8, 6))
(sf1, sf2), (sf3, sf4) = fig.subfigures(2, 2)
# Forest plot
(
so
.Plot(beta_summary.to_pandas(), x="groups")
.add(so.Range(alpha=0.7), ymin="beta_lower", ymax="beta_upper")
.add(so.Dot(color="steelblue"), y="beta")
.label(x="group", y="beta", title="Forest plot")
.on(sf1)
.plot()
)
# Density
(
so
.Plot(beta_df.to_pandas(), x="beta", color="groups")
.add(so.Area(alpha=0.5), so.KDE(common_norm=False))
.label(x="beta", y="density", title="Posterior density")
.on(sf2)
.plot()
)
# Prior vs posterior
(
so
.Plot(compare.to_pandas(), x="beta", color="source")
.facet(col="groups", wrap=2)
.add(so.Area(alpha=0.5), so.KDE(common_norm=False))
.label(x="beta", y="density", title="Prior vs posterior")
.on(sf3)
.plot()
)
# Predictive fit
(
so
.Plot(pred_summary.to_pandas(), x="x", color="group")
.add(so.Band(alpha=0.25), ymin="mu_lower", ymax="mu_upper")
.add(so.Line(), y="mu")
.label(x="x", y="mu", title="Predictive fit")
.on(sf4)
.plot()
)
fig
alt.data_transformers.enable("vegafusion")
# Forest plot
alt_forest = (
alt
.layer(
alt
.Chart(beta_summary.to_pandas())
.mark_errorbar(ticks=True)
.encode(x="groups:N", y="beta_lower:Q", y2="beta_upper:Q"),
alt
.Chart(beta_summary.to_pandas())
.mark_point(color="steelblue")
.encode(x="groups:N", y="beta:Q"),
alt
.Chart(pd.DataFrame({"y0": [0]}))
.mark_rule(color="#888888", strokeDash=[4, 4])
.encode(y="y0:Q"),
)
.resolve_scale(y="shared")
.properties(title="Forest plot", width=200, height=200)
)
# Density
alt_density = (
alt
.Chart(beta_df.to_pandas())
.transform_density("beta", groupby=["groups"], as_=["beta", "density"])
.mark_area(opacity=0.5)
.encode(x="beta:Q", y="density:Q", color="groups:N")
.properties(title="Posterior density", width=200, height=200)
)
alt_compare = (
alt
.Chart(compare.to_pandas())
.transform_density("beta", groupby=["groups", "source"], as_=["beta", "density"])
.mark_area(opacity=0.5)
.encode(x="beta:Q", y="density:Q", color="source:N")
.properties(width=95, height=85)
.facet("groups:N", columns=2)
.properties(title="Prior vs posterior")
)
# Predictive fit
alt_pred = (
alt
.layer(
alt
.Chart(pred_summary.to_pandas())
.mark_area(opacity=0.25)
.encode(x="x:Q", y="mu_lower:Q", y2="mu_upper:Q", color="group:N"),
alt
.Chart(pred_summary.to_pandas())
.mark_line()
.encode(x="x:Q", y="mu:Q", color="group:N"),
)
.resolve_scale(y="shared")
.properties(title="Predictive fit", width=200, height=200)
)
(
alt.hconcat(alt_forest, alt_density) & alt.hconcat(alt_compare, alt_pred)
).resolve_scale(color="independent")
Posterior forest plot, density, prior vs posterior, and predictive fit via Altair.
Install
If you want the latest functionality merged into main but not yet released, install directly from GitHub:
uv add git+https://github.com/drbenvincent/tidydraws.git
If you want the latest functionality merged into main but not yet released, install directly from GitHub:
pip install git+https://github.com/drbenvincent/tidydraws.git
Why tidydraws?
Plotting MCMC output in Python means manually slicing xarray dimensions, iterating groups, and aligning coordinates — imperative, verbose, error-prone. R’s tidybayes solved this with a data layer that respects parameter space vs prediction space. tidydraws brings that to Python on Polars.
tidydraws is plotting-backend-agnostic: it returns Polars DataFrames, and .to_pandas() bridges to lets-plot, plotnine, or any library that takes pandas. The examples use lets-plot; see the parameter_draws() page for the same plot in plotnine.
Inspired by tidybayes for R.